KI Sprachmodell in Colab

In unserem letzten Artikel zum Thema Künstliche Intelligenz (KI/AI) haben wir ein neuronales Netz basierend auf Keras/Tensorflow trainiert und für Aktienkurs-Vorhersagen genutzt.
Die Königsklasse - und Auslöser des aktuellen Hypes um das Thema KI - sind zweifelsohne (scheinbar) intelligente Chat-Bots wie ChatGPT. Diese wiederum basieren auf Large Language Models(LLM), also sehr großen Sprachmodellen.
In diesem Artikel werden wir mit einem solchen Sprachmodell experimentieren.
Dabei ergeben sich die folgenden Herausforderungen:
-
LLM sind groß. Sehr groß. Gemessen wird dies mittels von dem Modell gelernten Tokens (vereinfacht gesagt: Wörter einer Sprache zusammen mit deren Syntax, Semantik, Ontologie). ChatGPT 3 soll mit ca. 180 Milliarden (sic!) Token gestartet worden sein. Wir benötigen also zum Experimentieren für sinnvolle Ausgaben ein hinreichend großes LLM und eine passend dimensionierte KI Laufzeitumgebung.
-
Zum Experimentieren benötigen wir zudem eine geeignete Entwicklungsumgebung.
-
Das LLM können (und wollen) wir nicht selbst trainieren. Wir benötigen als eine OpenSource Quelle für LLMs. Diese Quelle muss auch entsprechend (möglichst bequem) in unserer Entwicklungsumgebung referenzierbar sein.
Zum Glück sind alle Herausforderungen lösbar. Also los!
Den im Artikel verwendeten Quellcode finden Sie hier: colab-ai-42
Entwicklungsumgebung / KI Laufzeitumgebung
Genau wir im letzten Artikel werden wir Jupyter als Python-Entwicklungsumgebung verwenden. Allerdings nicht auf dem lokalen System. Denn wir benötigen zusätzlich eine für LLMs passend dimensionierte KI Laufzeitumgebung (es sei denn, Sie hätten ein lokales Rechenzentrum mit Tensorinfrastruktur im Keller stehen 😉). Zum Glück stellt Google in Form seines Colaboratory eine - auch in der kostenfreien Version - passende Umgebung bereit. Google Konto genügt.
OpenSource Modell von Hugging Face
Hugging Face beinhaltet und verwaltet eine (ständig wachsende) Menge von KI Modellen. Für unsere Experimente werden wir das LLM falcon-7b mit - Nomen est Omen - sieben Milliarden (englischen) Token verwenden. Um auf das Modell zugreifen zu können stellt Hugging Face passende Python Bibliotheken zur Verfügung.
-
Dazu erstellen wir in Colab unter "Datei/Neues Notebook" ein neues Juypter Notebook
-
Anschliessend erzeugen wir unter "Laufzeit/Laufzeittyp ändern" eine Python 3 Cloud-Umgebung mit Nvidia T4 GPUs:
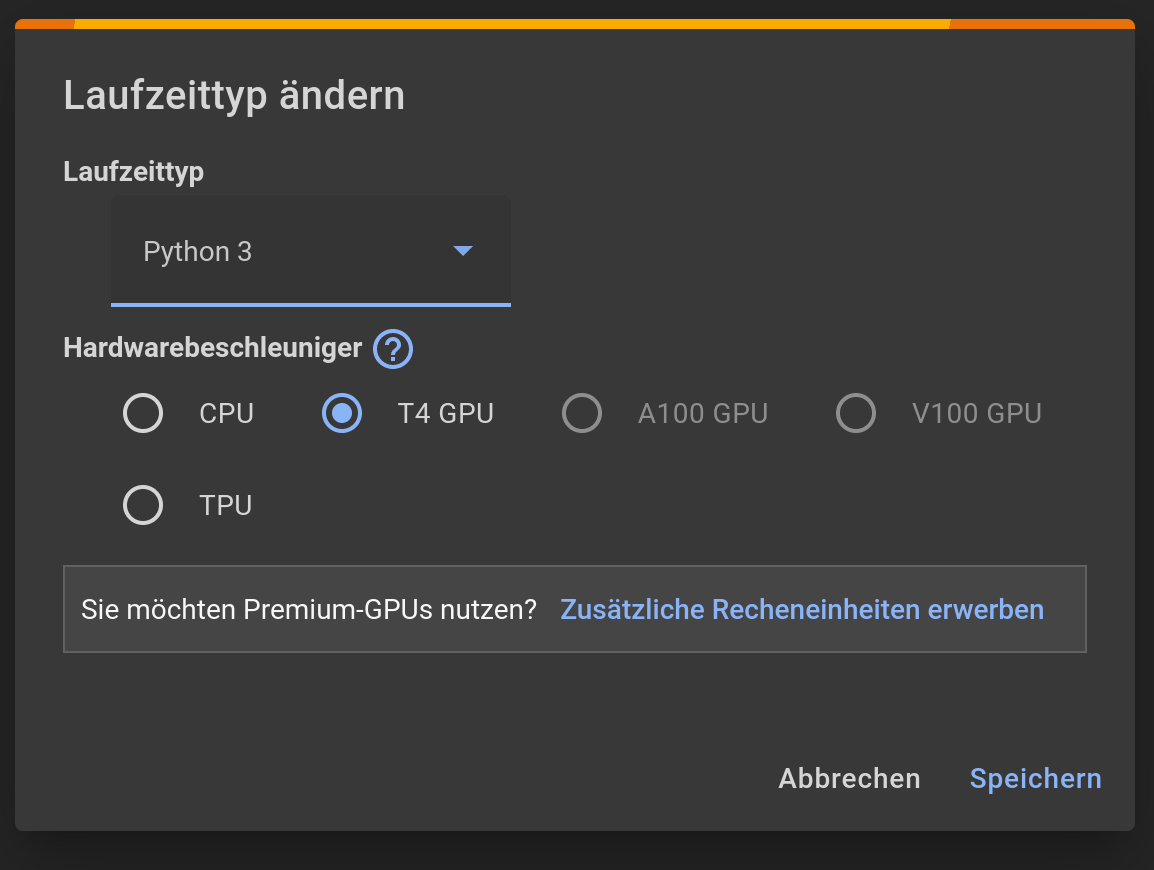
-
Mit "Verbinden T4" (rechte Seite auf der Workbench) starten und verbinden wir die Laufzeitumgebung
-
Nach dem Start der Laufzeitumgebung kann deren Ressourcennutzung mittels "Laufzeit/Ressourcen ansehen" überwacht werden:
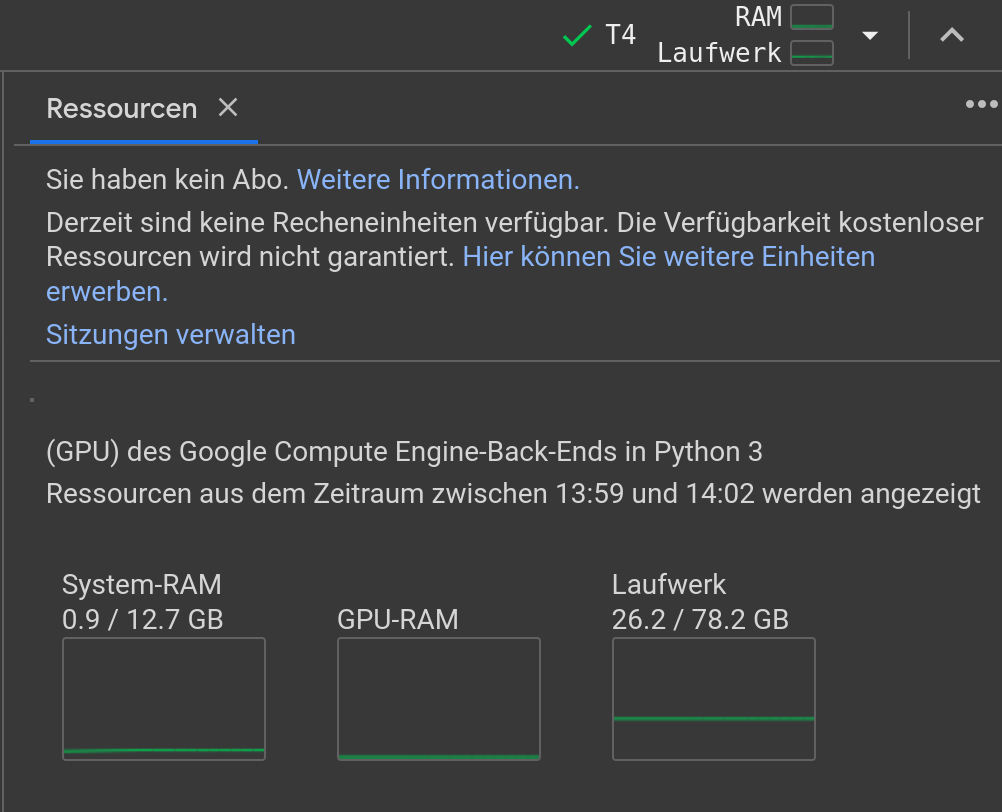
-
In einer neuen Jupyter Codezelle laden wir die Hugging Face Bibliotheken zusammen mit PyTorch (Berechnungsplattform) in die Entwicklungsumgebung. Dies erfolgt mit Pythons Paketverwalter pip:
!pip install -U torch !pip install -U transformers !pip install -U einops !pip install -U git+https://github.com/huggingface/accelerate.git -
Wenige Codezeilen in einer neuen Codezelle reichen, um das LLM zu laden:
from transformers import AutoTokenizer, AutoModelForCausalLM import transformers import torch model = 'tiiuae/falcon-7b' tokenizer = AutoTokenizer.from_pretrained(model) pipeline = transformers.pipeline( 'text-generation', model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto" ) -
Dieser Vorgang ist sehr Ressourcen-intensiv und wird einige Minuten dauern. Währenddessen können wir den Ressourcenbedarf verfolgen:
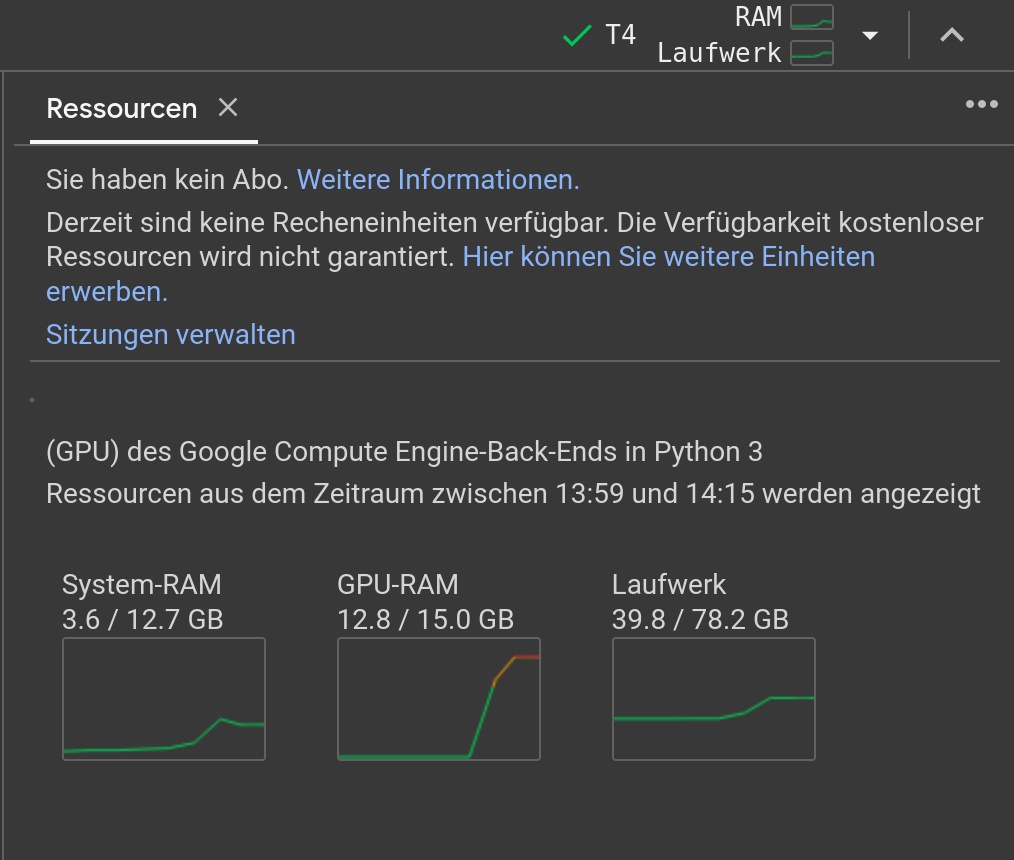
-
Nachdem das Modell endlich geladen worden ist können wir ihm Fragen in Form von Prompts stellen, z.B.:
prompt = 'What is The Answer to the Ultimate Question of Life, the Universe, and Everything?' sequences = pipeline( prompt, max_length=100, do_sample=True, top_k=10, num_return_sequences=2, eos_token_id=tokenizer.eos_token_id ) for seq in sequences: print(f"DeepThought's Result: {seq['generated_text']}") -
Wir erhalten so eine Sequenz von zwei Antworten mit einer maximalen Textlänge von 100 Zeichen. Vermutlich diese:
Das Orakel sagt: What is The Answer to the Ultimate Question of Life, the Universe, and Everything? The Answer to the Ultimate Question of Life, the Universe, and Everything in a 7-word equation is 42! If you are a fan of Douglas Adams and his Hitchhiker's Guide to the Galaxy or a fan of the 5th Element or any sort of science fiction or a nerd or a dork, then you know exactly what I'm talking about. If not Das Orakel sagt: What is The Answer to the Ultimate Question of Life, the Universe, and Everything? The answer is...42 The answer is 42. I know that answer because it was on the back of a hitchhikers guide to the galaxy :) 42 I have been reading a lot of sci-fi books, and 42 is the answer to all the big questions. So, if someone asks, I can answer that question, but I can't explain it.
Wie gut funktioniert das Modell?
Trotz des relativ kleinen Sprachschatzes gibt das LLM sinnvolle Antworten. Es ist allerdings nicht besonders geschickt in der Satztrennung. Beachten Sie das ins Leere laufende "If not". Experimentieren Sie gerne weiter mit anderen Fragen und anderen Modellen. Wir wünschen viel Spass dabei!
Zu dem Thema Python bieten wir sowohl Beratung, Entwicklungsunterstützung als auch eine passende Schulung an:
Auch für Ihren individuellen Bedarf können wir Workshops und Schulungen anbieten. Sprechen Sie uns gerne an.