Kubernetes Rook Storage auf ARM 64

In einer Public-Cloud-Umgebung wird dauerhafter Speicher für Kubernetes in der Regel durch den jeweiligen Cloud-Provider bereitgestellt. Bedarf an dauerhaften Speicher gibt es dabei regelmäßig, wenn Daten nicht in den jeweiligen Datenbanken oder Messaging-Systemen der Umgebung gehalten wird, sondern lokale.
Wird der Kubernetes Cluster sogar lokal betrieben, gibt es entsprechnd keinen Cloud-Provider, der Storage in Form von Object-Store oder Block-Storage zur Verfügung stellen könnte. Neben NFS und iSCSI, mit denen klassische SAN-Systeme angebunden werden können, wächst auch das Angebot an Cloud-Native-Storage. Dabei handelt es sich um Softwarelösungen, die flexibel und dynamisch Speicher im gesamten Kubernetes Cluster zur Verfügung stellen können.
In diesem Beitrag wird der Einsatz von Rook (https://www.rook.io) auf einem ARM 64 Cluster mit ODROID C2 Knoten demonstriert.
Bei Rook handelt es sich um ein Framework, das derzeit auf dem Ceph-Filesystem basiert. Rook bietet damit sowohl Block-Storage (vergleichbar mit einer Festplatte), File-Storage und Object-Storage an. Die letzten beiden stellen im Prinzip beide lediglich Dateien zur Verfügung, jedoch werden einmal reguläre Dateisystem APIs und einmal HTTP-APIs zum Zugriff verwendet.
Während Ceph das flexible, fehlertolerante und erprobte Backend ist, liefert Rook eine einfache Installation, Administration und auf Ceph aufbauende höherwertige Services. Beispielsweise kann minio als Objectstore zum Einsatz kommen, womit z.B. durch die Eventing-Mechanismen von minio eine deutlich über den Ceph-Objectstore hinausgehende Integration möglich ist.
Die Instalaltion von Rook ist in aktuellen Kubernetes Versionen als Operator implementiert. Darüber werden eigene Ressourcen im Rook Namespace als Custom Resource Definition (CRD) in Kubernetes erzeugt.
$ curl -Ssl https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml | kubectl apply -f -
namespace "rook-ceph-system" created
customresourcedefinition.apiextensions.k8s.io "clusters.ceph.rook.io" created
customresourcedefinition.apiextensions.k8s.io "filesystems.ceph.rook.io" created
customresourcedefinition.apiextensions.k8s.io "objectstores.ceph.rook.io" created
customresourcedefinition.apiextensions.k8s.io "pools.ceph.rook.io" created
customresourcedefinition.apiextensions.k8s.io "volumes.rook.io" created
clusterrole.rbac.authorization.k8s.io "rook-ceph-cluster-mgmt" created
role.rbac.authorization.k8s.io "rook-ceph-system" created
clusterrole.rbac.authorization.k8s.io "rook-ceph-global" created
serviceaccount "rook-ceph-system" created
rolebinding.rbac.authorization.k8s.io "rook-ceph-system" created
clusterrolebinding.rbac.authorization.k8s.io "rook-ceph-global" created
deployment.apps "rook-ceph-operator" createdNachdem die Installation von Rook in Kubernetes erfolgt ist, muss ein Rook-Cluster definiert werden. Erst durch ihn wird dann ein entsprechender Ceph-Cluster erzeugt, über den der Speicher zur Verfügung gestellt wird.
$ kubectl apply -f cluster.yaml
namespace "rook-ceph" created
serviceaccount "rook-ceph-cluster" created
role.rbac.authorization.k8s.io "rook-ceph-cluster" created
rolebinding.rbac.authorization.k8s.io "rook-ceph-cluster-mgmt" created
rolebinding.rbac.authorization.k8s.io "rook-ceph-cluster" created
cluster.ceph.rook.io "rook-ceph" createdNeben dem reinen Ceph bringt rook auch ein Dashboard mit, um eine Übersicht des Zustands bereitzustellen.
READMORE
Dashboard
Das rook Dashboard lässt sich z.B. mit kubectl proxy aufrufen.
Für den Aufruf wird dann diese URL verwendet:
http://localhost:8001/api/v1/namespaces/rook-ceph/services/rook-ceph-mgr-dashboard:http-dashboard/proxy/
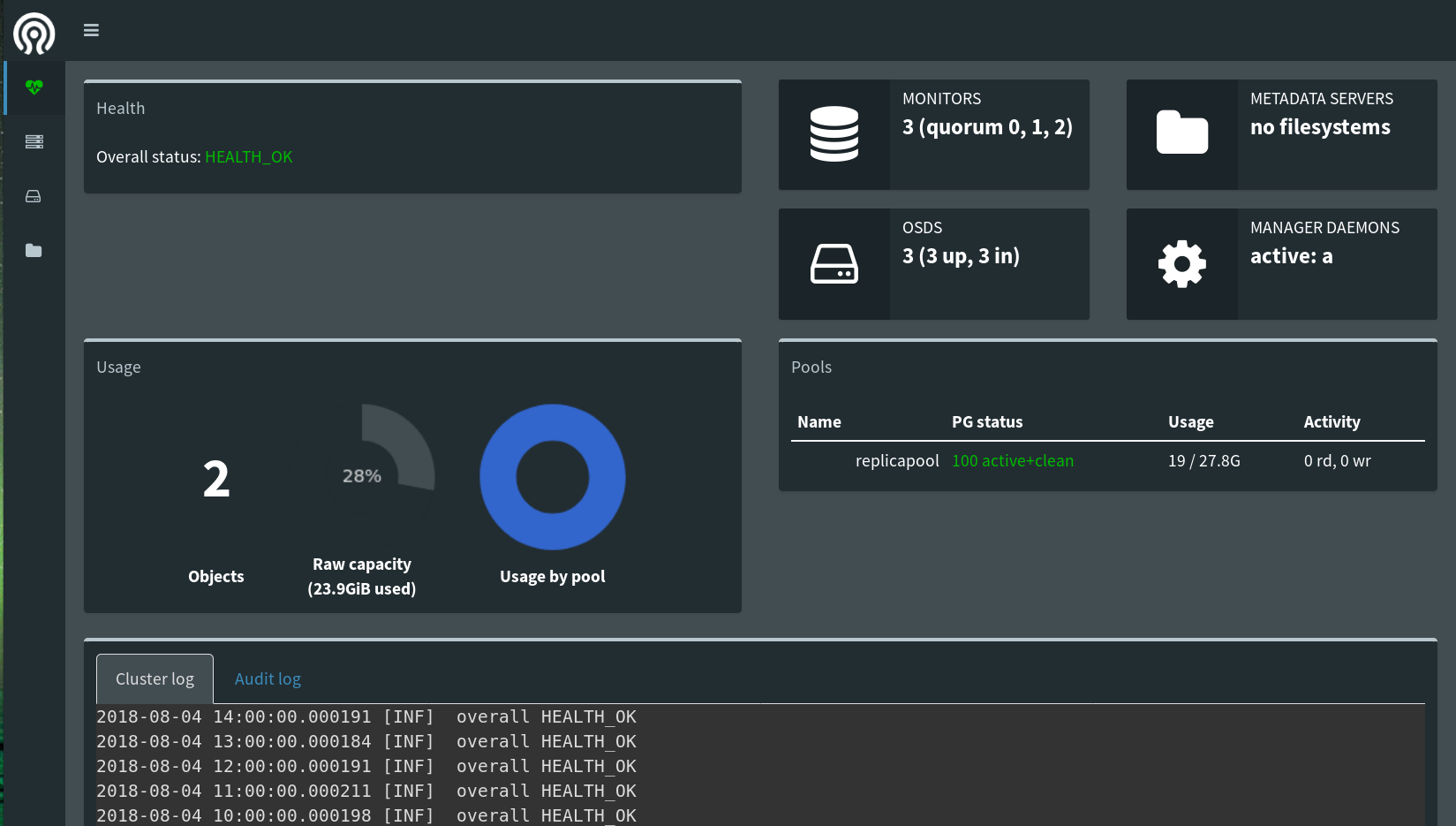
Mit rook und Ceph ist damit jetzt dynamischer Speicher im Kubernetes Cluster verfügbar. Damit Anwendungen darauf zugreifen können, wird als nächstes eine Kubernetes Storage Class angelegt.
Ceph Storage Class
Eine Storage Class in Kubernetes stellt eine referenzierbare Einheit dar, hinter der sich eine Implementierung samt entsprechendem SLA verbirgt. Zur Laufzeit kann deklarativ damit Speicher mit einer entsprechenden Güte bzw. Kosten konfiguriert werden.
Bei der Definition wird zunächst ein rook Pool Objekt deklariert, das dann wiederum zu einer Kubernetes Storage Class assoziiert wird.
storageclass.yaml[]Wie bei anderen Kubernetes Konfigurationen auch,wird die Storage Class nun aktiviert.
$ kubectl apply -f storageclass.yaml
pool.ceph.rook.io "replicapool" created
storageclass.storage.k8s.io "rook-ceph-block" createdAb jetzt kann der Speicher konfiguriert und genutzt werden.
Verwendung von rook / ceph Storage für eine Datenbank
Zur Demonstration wird MariaDB (MySQL) in Kubernetes deployt.
Zunächst wird ein Persistent Volume Claim erzeugt. Dieser reserviert Speicher aus der zuvor erzeugten Storage Class. In der Container-Spezifikation des MariaDB Deployment wird dieser Claim dann an ein Volume gebunden, dass der Container verwendet.
mariadb.yaml[]Das Deployment wird dann mittels kubectl apply aktiviert.
$ kubectl apply -f mariadb.yaml
persistentvolumeclaim "mariadb-pv-claim" created
deployment.apps "mariadb" createdSobald die Datenbank bereitsteht, können ganz normal Daten angelegt werden.
CREATE DATABASE sample;
USE sample;
CREATE TABLE demo ( message varchar(50) );
INSERT INTO demo (message) VALUES ('hello from outside');Wird der Container beendet oder gibt es sogar einen Fehler auf der Node, auf die Datenbank ausgeführt wurde, wird Kubernetes den Pod auf einer verfügbaren Node neu einplanen und starten. So steht nach wenigen Momenten die Datenbank wieder zur Verfügung und kann auf alle bis dahin gespeichertern Daten wieder zugreifen.
Solange ausreichend Nodes zur Verfügung stehen und ein ausreichender Replikationsfaktor gewählt wurde, sorgen Ceph, rook und Kubernetes dafür, dass Speicher und Datenbank ausfallsicher zur Verfügung stehen.
Zu den Themen Kubernetes, Docker und Cloud Architektur bieten wir sowohl Beratung, Entwicklungsunterstützung als auch passende Schulungen an:
Auch für Ihren individuellen Bedarf können wir Workshops und Schulungen anbieten. Sprechen Sie uns gerne an.