Kubernetes NFS Volume mit Raspberry PI

Ein Mini-Cluster für Kubernetes eignet sich hervorragend für Experimente und zum Training. Wie beispielsweise in Kubernetes Cluster mit Raspberry Pi erklärt, eignen sich für einen kostengünstigen Start Raspberry Pi Minicomputer ausgezeichnet. Leider ist ARM aktuell nicht im Fokus der diversen Cloud-Native Storage Lösungen, so dass sich als Alternative ein externes Volume anbietet. Das häufig anzutreffende Synology NAS bietet NFS Support. Wie sich dies mit Kubernetes einsetzen lässt, wird im folgenden illustriert.
Synology Konfiguration für Kubernetes
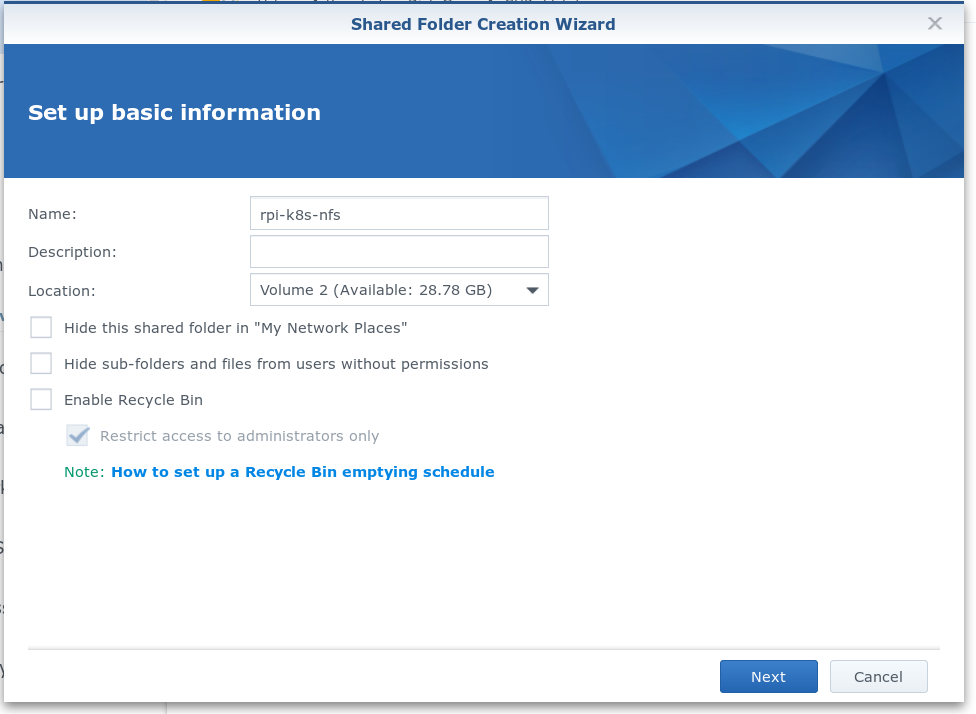
Zunächst bietet es sich an, ein separates Volume für die Kubernetes Experimente anzulegen. Wenn dabei etwas schief geht, spart das viel Sorge um wichtige Daten.
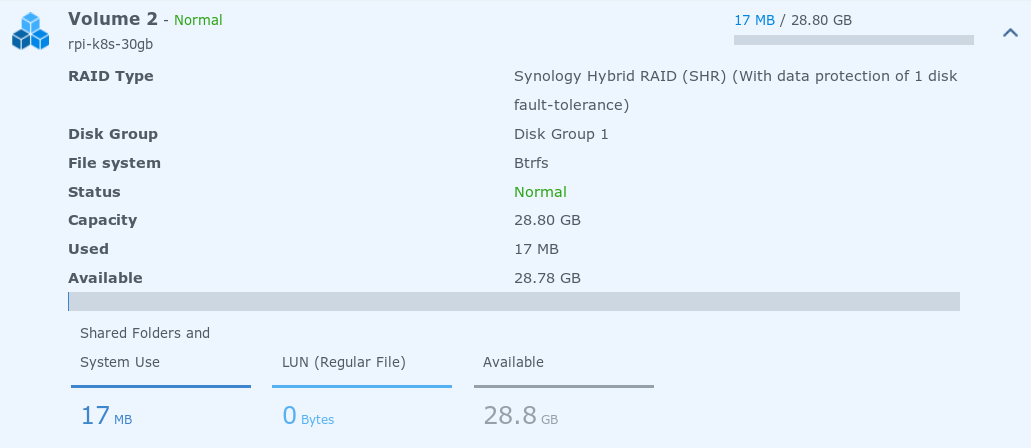
Damit Kubernetes via zugreifen kann, muss der NFS Server im Synology NAS aktiviert sein.
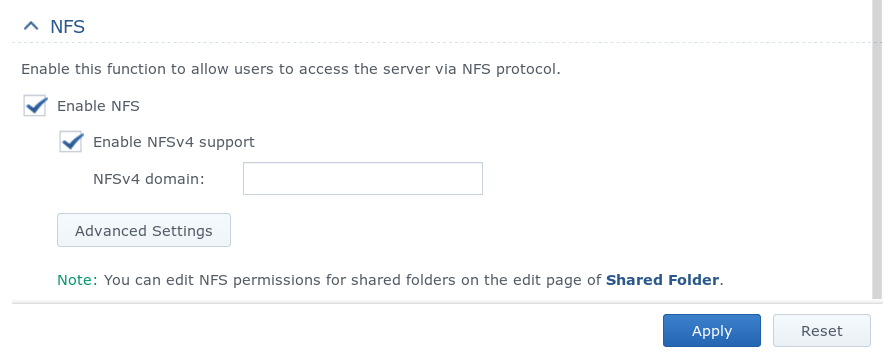
Das Volume selbst muss nun ebenfalls noch als Shared Folder freigegeben werden. Daraus leitet sich auch der zu verwendende NFS Pfad beim späteren mounten ab. Bei Synology wird das Volume über das Control Panel/Shared Folders als neue Freigabe angelegt. Wichtig ist hier noch den Papierkorb (Recycle Bin) zu deaktivieren, damit der Client wirklich die volle Kontrolle über Dateioperationen erhält.
Nachdem ein Export erzeugt wurde, müssen noch Berechtigungen erteilt werden, damit Clients auf den Ordner zugreifen können. Dazu kann am einfachsten über die IP Adresse des Clients der Zugriff entschieden werden. Entsprechend kann für das lokale Subnet eine generelle Erlaubnis konfiguriert werden.
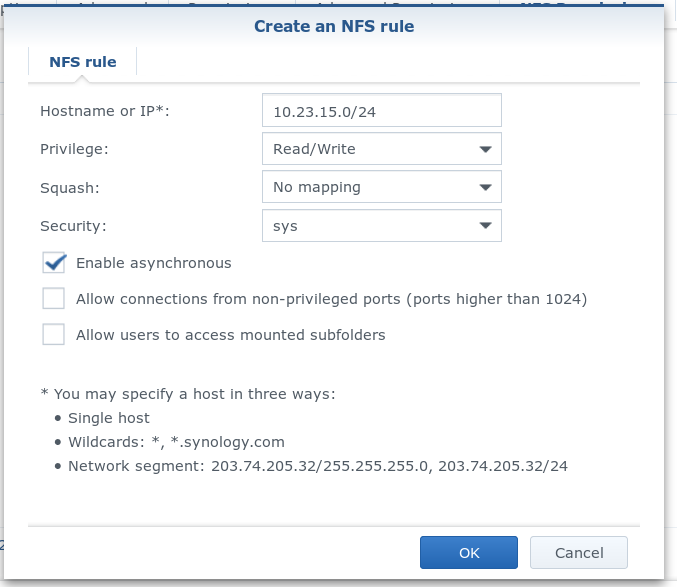
Ist die Konfiguration soweit abgeschlossen, sollte noch der im Dialog unten rechts angezeigte "Mount path" beachtet werden.
Unter diesem Pfad ist das Volume jetzt per NFS zu erreichen.
Entsprechend muss der Pfad in Kubernetes verwendet werden, um das Persistent-Volume zu deklarieren, im Beispiel ist es /volume2/rpi-k8s-nfs.
Wichtig ist, dass der jeweilige Host, der ein NFS Volume nutzen soll, die notwendigen Werkzeuge installiert haben muss. In er Regel werden diese als nfs-utils paketiert.
Kubernetes Konfiguration für NFS
Ein kurzer Test, ob der NFS Export funktioniert kann mit Linux Bordmitteln durchgeführt werden.
Unter Ubuntu muss das Paket nfs-common vorhanden sein.
$ sudo mount 10.23.15.1:/volume2/rpi-k8s-nfs /mnt
$ sudo touch /mnt/demo
$ sudo rm /mnt/demo
$ sudo umount /mntKubernetes stellt Speicher als PersistentVolume Objekt in der API zur Verfügung.
Darüber kann nun das durch NFS bereitgestellte Volume in Kubernetes bekanntgegeben werden.
Bevor das erfolgen kann, sollte jedoch eine Definition der Storage-Klasse erfolgen. Normalerweise verwendet Kubernetes Provisioner, bei denen dynamisch Speicherplatz angefordert werden kann. In Cloud-Umgebungen werden durch den entsprechenden Anbieter die erforderlichen APIs angeboten.
Bei dem manuell eingerichteten NFS ist das nicht der Fall. Entsprechend wird als Provisioner ein String angegeben, der auf kein Plugin für Kubernetes Provisioning passt.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
provisioner: manual/call-admin
parameters:
type: nfs
reclaimPolicy: Retain
mountOptions:Bei der Konfiguration wurde als Reclaim-Policy die Retain Strategie gewählt:
Wenn ein Pod beendet wird, soll der Speicher erhalten bleiben und ggf. durch einen anderen oder neu gestarteten Pod weiter verwendet werden können.
apiVersion: v1
kind: PersistentVolume
metadata:
name: syn-volume
spec:
capacity:
storage: 28Gi
storageClassName: standard
accessModes:
- ReadWriteMany
nfs:
server: 10.23.15.1
path: "/volume2/rpi-k8s-nfs"
persistentVolumeReclaimPolicy: RetainWie üblich wird durch kubectl die Konfiguration aktiviert.
Anschließend wird das Objekt auch in der API ausgegeben.
$ kubectl -n default apply -f syn-nfs.yaml
persistentvolume "syn-volume" created
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
syn-volume 28Gi RWX Retain Available standard 2mVerwendung des PersistentVolume in einem Claim
Zunächst muss ein Claim auf das PersistentVolume eingerichtet werden. Da ein PersistentVolume stets nur einem Claim zugeordnet werden kann, wird auch genau ein Claim verwendet, der dann von allen Anwendungen gemeinsam genutzt werden kann. Darum wird der Claim auch nicht einer einzelnen Anwendung zugeordnet. Die jeweilige Anwendung bekommt dann ein Unterverzeichnis, um die Daten zu separieren.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: shared-pv-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: standard
resources:
requests:
storage: 28GiAnschließend wird der PersistentVolumeClaim angelegt. Zur Sicherheit kann noch eine Abfrage erfolgen, ob der Claim im Kubernetes korrekt vorliegt.
$ kubectl -n default apply -f nfs-claim.yaml
persistentvolumeclaim "shared-pv-claim" created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
shared-pv-claim Bound syn-volume 28Gi RWX standard 1mAb jetzt steht der Speicher zur Verwendung in Anwendungen zur Verfügung.
PersistentVolumeClaim mit MySQL
Zur Demonstration wird MySQL als Datenbank verwendet. Benötigt wird der Service, um MySQL als abstrakten Dienst in Kubernetes bereitzustellen und ein Deployment um die eigentliche Anwendung bereitzustellen.
Der MySQL Dienst soll als NodePort zur Verfügung gestellt werden, also auf allen Nodes des Cluster von außen erreichbar werden.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- port: 3306
nodePort: 30306
name: mysql
selector:
app: mysql
type: NodePort
ports:
- port: 3306Der Dienst benötigt nun noch ein Deployment, in diesem Fall mit einem Image, dass auf Raspberry Pi funktioniert.
Anders, als beispielsweise Postgresql, wird weder von MySQL noch von MariaDB ein ARM Image angeboten, daher wird hypriot/rpi-mysql verwendet.
Wichtig ist zudem, dass hier ein Unterverzeichnis des PersistentVolumeClaim verwendet wird, um die Daten des gemeinsam genutzten Volumes zwischen den Anwendungen im Kubernetes Cluster zu separieren.
Konfiguriert wird das Verhalten durch den subPath in der Container Spec.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
labels:
app: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: hypriot/rpi-mysql
name: mysql
env:
- name: "MYSQL_USER"
value: "mysql"
- name: "MYSQL_PASSWORD"
value: "mysql"
- name: "MYSQL_DATABASE"
value: "sample"
- name: "MYSQL_ROOT_PASSWORD"
value: "geheim"
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
subPath: mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: shared-pv-claimZugriff auf MySQL
Der MySQL Dienst wird als NodePort bereitgestellt und kann daher auch von außerhalb des Clusters aufgerufen werden.
$ kubectl get svc mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql NodePort 10.103.78.30 <none> 3306:30306/TCP 31m
$ mysql -u mysql -h 10.23.15.101 -P 30306 -pmysql sample -e "CREATE TABLE demo ( message varchar(50) );"
$ mysql -u mysql -h 10.23.15.101 -P 30306 -pmysql sample -e "INSERT INTO demo (message) VALUES ('hello from outside');"
$ mysql -u mysql -h 10.23.15.101 -P 30306 -pmysql sample -e "SELECT * from demo"Wird jetzt der Pod beendet, mit dem MySQL lief, wird Kubernetes einen neuen bereitstellen. Durch das gemeinsame Storage kann MySQL weiter Daten liefern.
$ kubectl get pods -l app=mysql -o wide
NAME READY STATUS RESTARTS AGE IP NODE
mysql-78954bf55d-fmpzx 1/1 Running 0 20m 10.40.0.5 rpi1-worker0
$ kubectl delete pod mysql-78954bf55d-fmpzx
pod "mysql-78954bf55d-fmpzx" deleted
$ kubectl get pods -l app=mysql -o wide
NAME READY STATUS RESTARTS AGE IP NODE
mysql-78954bf55d-rk62s 1/1 Running 0 2m 10.32.0.8 rpi2-worker1
$ mysql -u mysql -h 10.23.15.101 -P 30306 -pmysql sample -e "SELECT * from demo"
+--------------------+
| message |
+--------------------+
| hello from outside |
+--------------------+Fazit
Für erste Experimente ist dies manuelle Verfahren geeignet. Durch die fehlende Separierung des Speicherplatzes ist es erforderlich, sehr genau darauf zu achten, welchen Pfad eine Anwendung nutzt. Andernfalls kann es zu Datenverlust kommen.
Kubernetes unterstützt dazu die separate dynamische Provisionierung von Speicherplatz.
In Cloudumgebungen wird dies durch den jeweiligen Cloudprovider umgesetzt, bei eigenen Umgebungen kann eine Softwarelösung wie Ceph oder GlusterFS helfen.
Speziell für NFS gibt es im Kubernetes-Incubating Repository einen nfs-client Provisioner, mit dem sich das dynamische Verhalten auch auf NFS Storage abbilden lässt.
Zu den Themen Kubernetes, Docker und Cloud Architektur bieten wir sowohl Beratung, Entwicklungsunterstützung als auch passende Schulungen an:
Auch für Ihren individuellen Bedarf können wir Workshops und Schulungen anbieten. Sprechen Sie uns gerne an.